# Virtualisation « lourde »
- Avantages :
- Bonne isolation entre machines virtuelles
- Contrôle complet de l'environnement d'exécution
- Options pour le partage de périphériques matériel
- Gestion des ressources disponibles simple
- Désavantages :
- Besoin en authentification, journalisation, etc.
- Gestion de l'ensemble du système d'exploitation
- Sécurité des éléments matériels partagés ?
- Ressources disponibles fixes
Résultat : Plusieurs services par machine virtuelle
---
- Sans nécessairement utiliser la virtualisation
- Démarrage rapide
- Durée de vie variable (usage unique, récurrent, long terme, etc.)
- Fonctionnalité ancienne (début dans la branche 2.4!) mais étendue « récemment »
**Note :** La nomenclature et les limites sont floues. Concepts souvent mélangés.
# Podman : architecture
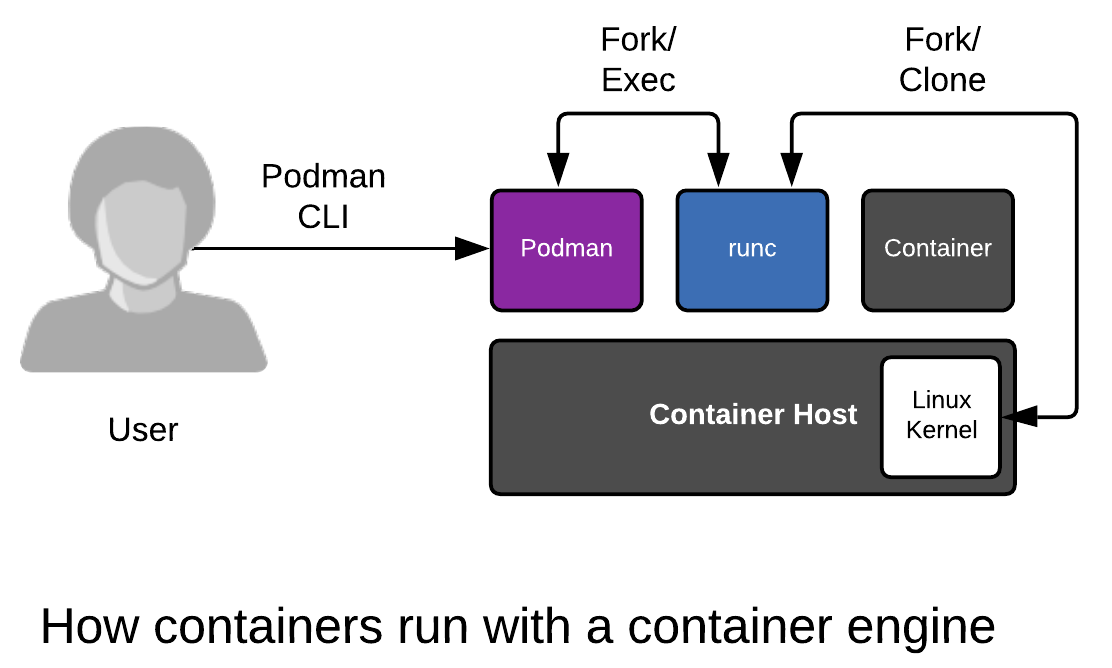
<https://www.redhat.com/en/blog/why-red-hat-investing-cri-o-and-podman>
---
# rkt (~Podman) vs Docker
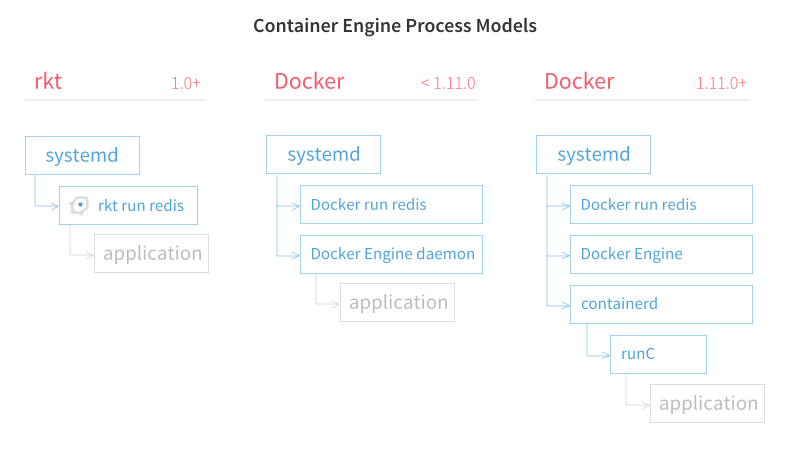
<https://coreos.com/rkt/docs/latest/rkt-vs-other-projects.html>
---
- Images de conteneur (archive tar + metadata json) :
- Docker Format v2 (standard *de facto*)
- OCI Image Format Specification
- OCI Runtime Specification (`runc`, `crun`)
- OCI Distribution Specification
# Conteneurs et applications graphiques
---
# Conteneurs et applications graphiques
- Sandboxing d'applications graphiques :
- Flatpak (voir Flathub)
- Firejail
- Snapcraft ou Snaps (principalement sous Ubuntu)
- Attention : Wayland nécesssaire. Le serveur d'affichage X.org ne peut pas
être configuré de façon sécurisée
- Systèmes d'exploitation centrés sur les conteneurs :
- Fedora Atomic Desktops (Silverblue, Kinoite, Sericea, Onyx)
- Endless OS, OpenSuse MicroOS / Aeon / Kalpa, Vanilla OS
- Ubuntu Core
---